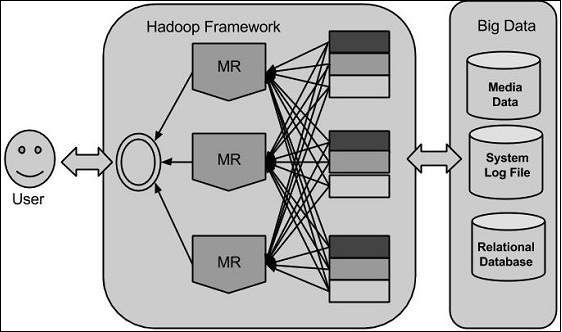
Hadoop
MapReduce is a software framework for easily writing
applications which process big amounts of data in-parallel on large
clusters (thousands of nodes) of commodity hardware in a reliable,
fault-tolerant manner.
The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input
data and converts it into a set of data, where individual elements are
broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map
task as input and combines those data tuples into a smaller set of
tuples. The reduce task is always performed after the map task.
Typically both the input and the output are stored in a file-system.
The framework takes care of scheduling tasks, monitoring them and
re-executes the failed tasks.
The MapReduce framework consists of a single master JobTracker and one slave TaskTracker
per cluster-node. The master is responsible for resource management,
tracking resource consumption/availability and scheduling the jobs
component tasks on the slaves, monitoring them and re-executing the
failed tasks. The slaves TaskTracker execute the tasks as directed by
the master and provide task-status information to the master
periodically.
The JobTracker is a single point of failure for the Hadoop MapReduce
service which means if JobTracker goes down, all running jobs are
halted.